 Eind 2011 zette Marc Drees vraagtekens bij de bruikbaarheid van Jobfeed-cijfers voor het bepalen van het online vacaturevolume, uitgedrukt in unieke vacatures. Jobfeed liet een stijgende lijn zien, terwijl andere economische indicatoren op een neerwaartse trend wezen.
Eind 2011 zette Marc Drees vraagtekens bij de bruikbaarheid van Jobfeed-cijfers voor het bepalen van het online vacaturevolume, uitgedrukt in unieke vacatures. Jobfeed liet een stijgende lijn zien, terwijl andere economische indicatoren op een neerwaartse trend wezen.
De Jobfeed ontdubbeling is in het verleden vooral gericht geweest op het vermijden van onterechte doublures, in combinatie met het bieden van een op individueel vacatureniveau bruikbare signalering van dubbelen. Marc’s artikel, en onze analyse daarna laat zien dat de sterke opkomst van gratis vacaturesites en het toenemende gebruik van automatische reposting de trendcijfers aanzienlijk heeft beinvloedt. Dit, en het toenemende gebruik van Jobfeed data als economische indicator, heeft Textkernel aan het werk gezet om een sterk verbeterde ontdubbelingmethode te ontwikkelen, die nog steeds onterechte samenvoeging vermijdt, maar een veel hogere prestatie levert in het wegfilteren van doublures.
Textkernel heeft een sterk op machine learning gebaseerde ontdubbelingsmethode ontwikkeld, waardoor dubbele vacatures beter aan elkaar gekoppeld worden. Jobfeed is daardoor in staat om zeker 90% van de dubbelen te herkennen. Dit was eerder 75%.
Zelfs vacatures die door een werkgever zijn geplaatst en door een intermediair deels zijn herschreven, worden nu regelmatig als dubbel gezien. Zie onderstaand voorbeeld:

Moeilijkheden
Van kwalitatief goede vacatures worden nu vrijwel alle dubbelen gevonden. Maar helaas zijn de vacatureteksten in de realiteit niet altijd zo duidelijk. Twee vacatures met een verschillende standplaats, maar verder identieke kenmerken, zijn in principe geen dubbelen van elkaar. Maar soms zijn “omgeving Amsterdam” en “Amstelveen” toch dubbelen. En wat te denken van “Utrecht” en “Amersfoort”? Als de provincie Utrecht bedoeld wordt, dan zijn dit waarschijnlijk dubbelen, anders wellicht niet. Dit soort gevallen zijn vrijwel niet af te vangen in de ontdubbelaar, want we willen nog steeds niet ten onrechte vacatures als dubbelen aanmerken.
Nieuwe ontdubbelingsmethode
De oude Jobfeed-ontdubbelingsmethode is gebaseerd op met de hand geschreven regels en tekstoverlap. Zoals het voorbeeld hierboven illustreert, is het zeer lastig om goede regels te schrijven. Daarom hebben we nu een andere aanpak gekozen: de toepassing van machine learning. Aan de hand van diverse kenmerken van twee vacatures (zoals tekstoverlap, titel, standplaats) wordt bepaald of twee vacatures dubbelen van elkaar zijn. Op basis van duizenden voorbeelden worden automatisch regels afgeleid die veel complexer zijn dan een mens kan maken. Dit levert een ontdubbelaar op die veel beter presteert. In Jobfeed en Textkernel CV parsing wordt overigens al jaren machine learning toegepast voor het extraheren van gegevens uit vacatures en CVs.
Verlengde ontdubbelingstermijn
Naast de verbetering van de herkenning van dubbelen, is de ontdubbelingstermijn verlengd van drie naar zes weken. Dit houdt in dat elke nieuw geplaatste vacature tot zes weken terug wordt ontdubbeld op inhoud. De oorspronkelijke termijn was drie weken omdat het ontdubbelingsproces veel rekenkracht kost. Deze verwerkingstijd is nu sterk teruggebracht. We zagen dat dubbele vacatures regelmatig buiten de termijn van drie weken geplaatst worden. Het gaat dan met name om (automatische) herplaatsingen op jobboards, of bulk imports van (oudere) vacatures van grote intermediairs op jobboards. Met de ontdubbelingstermijn van zes weken worden deze nu beter weggefilterd.
Impact
Om deze nieuwe methode in te voeren, zijn eenmalig alle vacatures in Jobfeed met terugwerkende kracht opnieuw ontdubbeld. Als gevolg daarvan is het aantal unieke vacatures met gemiddeld 25% afgenomen ten opzichte van de oude Jobfeed-cijfers (gemeten over de laatste drie jaar). Als we de vacatures van intermediairs niet meetellen, dan is de afname lager (rond 12,5%). Dit komt doordat vacatures van intermediairs gemiddeld meer vacatureplaatsingen hebben (op verschillende sites), en dus in grotere mate niet als dubbel herkend werden door de oude ontdubbelaar.
In onderstaande grafiek is de toename van het aantal vacatureplaatsingen in 2011 (blauwe lijn) duidelijk zichtbaar. In 2011 stijgt het oude aantal unieke vacatures (rode lijn) mee met het aantal plaatsingen, terwijl het nieuwe aantal unieke vacatures (oranje lijn) dat minder sterk doet. De stijging die in de eerste helft van 2011 overblijft is dus geen ontdubelingsfout, maar heeft werkelijk plaatsgevonden.
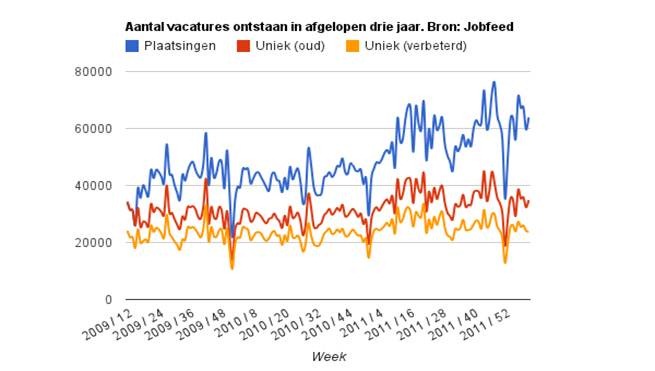
Het verschil tussen het oude en het nieuwe aantal unieke vacatures wordt over de jaren steeds groter. Dit wordt nog duidelijker in de grafiek hieronder. In 2009 is de afname rond de 20%, terwijl dit eind 2011 richting 30% gaat. Dit komt doordat vacatures op steeds meer sites worden geplaatst, terwijl niet alle dubbelen herkend werden. De opkomst van nieuwe gratis jobboards in 2011 heeft daaraan sterk bijgedragen door sterke stijging van het aantal dubbelplaatsingen.
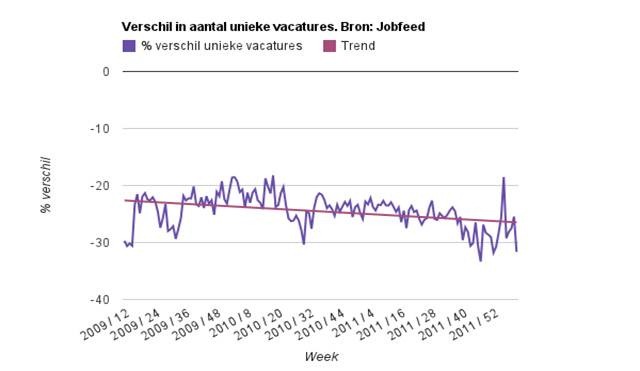
Hoewel hier in het algemeen geen grote trendbreuk te zien is, kan het zo zijn dat specifieke analyses die gemaakt zijn op basis van oude Jobfeed-cijfers nu op details anders uitpakken. Met de nieuwe ontdubbeling geeft Jobfeed in ieder geval een sterke verbetering van de betrouwbaarheid van het aantal unieke vacatures online. We houden verdere ontwikkelingen bij om te zorgen dat dit ook zo blijft.
Dit gastblog is geschreven door Ruud Liebregts (Product Manager) en Jakub Zavrel (oprichter) van Textkernel. Textkernel levert onder meer Jobfeed.
Mark
says:als gebruiker, lijkt dit mij een nutteloze verbetering. vermoedelijk blijven de getallen zwaar overdreven en zullen de absolute getallen nog niets zeggend zijn.
Marc Drees
says:Een bijzonder waardevolle reactie. En nu graag nog enig feitenmateriaal ter onderbouwing van de claims zwaar overdreven en nietszeggend.
Marco Hendrikse
says:Dit lijkt me een hele verbetering. Als dagelijkse gebruiker van Jobfeed had ik nogal ‘last’ van al die dubbele vacatures. Ik ga er de komende weken extra kritisch op zijn en indien nodig die feedback-knop gebruiken 😉