
h/t Benjamin Bearman
h/t Benjamin Bearman
 Iedereen heeft weleens meel in de mond gehad, toch? Een recent artikel van een nog niet nader te noemen HR Tech bedrijf laat zien dat nietszeggendheid tot kunstvorm kan worden verheven. Ik heb hieronder een aantal statements uit het betreffende artikel samengevoegd, waarbij ik het aan ieders arendsoog overlaat om in te schatten wie de achterliggende auteur is. En dan bedoel ik natuurlijk het bedrijf, niet de juridische commissie die dit geschreven heeft. De bedrijfsnaam is vervangen door <>. Veel leesplezier…
Iedereen heeft weleens meel in de mond gehad, toch? Een recent artikel van een nog niet nader te noemen HR Tech bedrijf laat zien dat nietszeggendheid tot kunstvorm kan worden verheven. Ik heb hieronder een aantal statements uit het betreffende artikel samengevoegd, waarbij ik het aan ieders arendsoog overlaat om in te schatten wie de achterliggende auteur is. En dan bedoel ik natuurlijk het bedrijf, niet de juridische commissie die dit geschreven heeft. De bedrijfsnaam is vervangen door <>. Veel leesplezier…
Wanneer iemand zijn of haar cv uploadt naar <> in de hoop een nieuwe baan te vinden, vertrouwt diegene zijn of haar gegevens aan ons toe.
Het is onze verantwoordelijkheid om deze gegevens te beschermen met de zorg en veiligheid die de carrièremogelijkheden van mensen verdienen. Bij <> staan privacy en gegevensbescherming centraal in de manier waarop we onze producten ontwikkelen.
ELIZA is een ai uit 1964.
Nu, 62 jaar later, kunnen ook recruiters eindelijk mentaal knallen.
Met de techniek van toen!
Zeg maar waar je last van hebt en druk op enter. Toe maar. Je gevoel mag er zijn. Gooi het er maar uit.
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
(meer…)
Waarom denken sommige mensen dat ai kan denken?
Omdat ai bedrijven daarover jokken.
Neem dat niet van mij aan, maar van hun eigen ai experts.
| Het bedrijf | Zegt dat ai… | Terwijl hun eigen ai expert zegt dat ai.. |
|---|---|---|
| OpenAI | denkt | niet denkt (Sutskever) |
| Microsoft | handelt als collega | niet handelt (Bubeck) |
| DeepMind | intelligent is | niets begrijpt (Silver) |
| Anthropic | redeneert | niet redeneert (Amodei) |
| Meta | mensachtig is | statistisch is (LeCun) |
Na een lange mars van twee jaar heeft China de koppositie overgenomen genomen van de verliezer van de maand, de Verenigde Staten. Opvallende stijger is Singapore. Ai in Rusland is op sterven na dood.
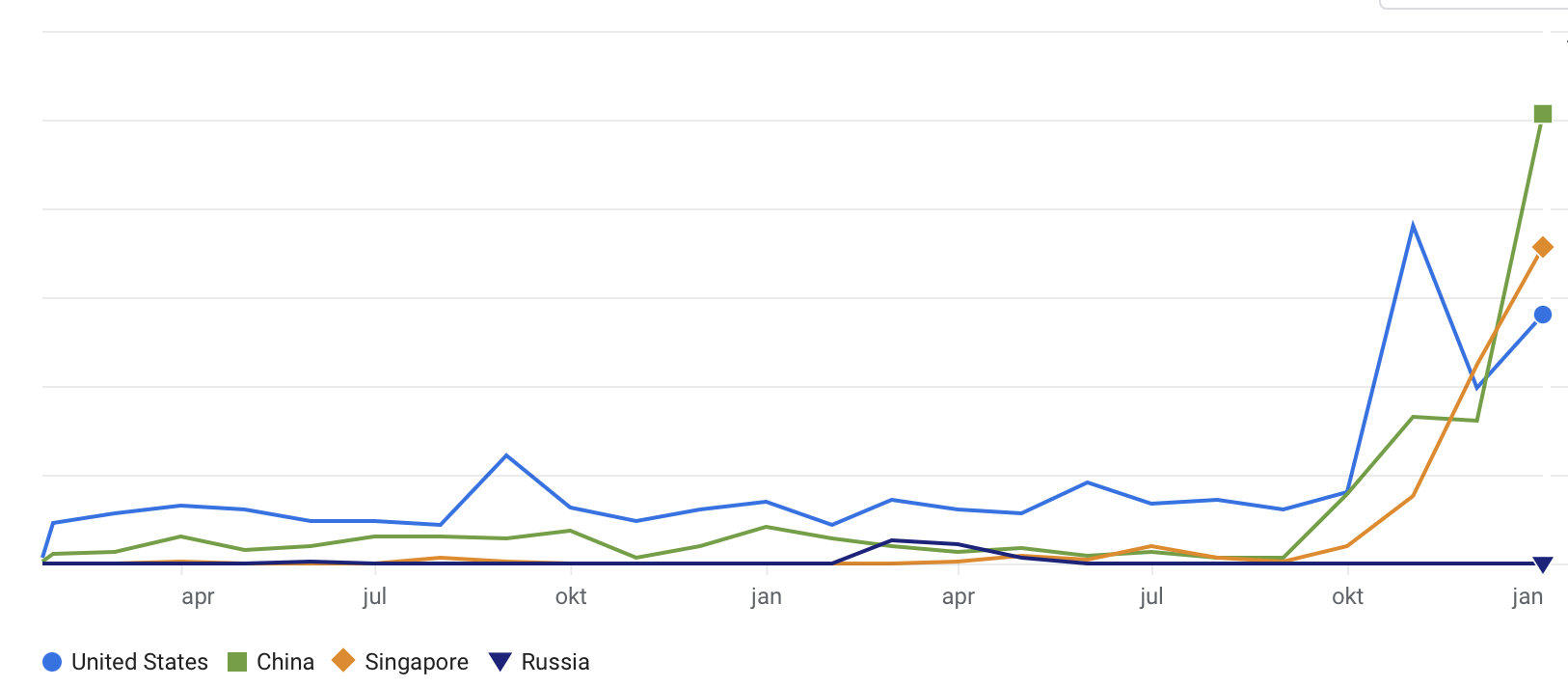
Ja. Nogal serieus. Staat ook in de krant. Die gooien er 24 miljard tegenaan.
(meer…)
Ben je bang dat ai uit verre landen bij ons de dienst gaat uitmaken? Ga dan vanavond naar The AI Strategy & Sovereignty Special.
Er zijn waarschijnlijk geen reguliere plaatsen beschikbaar. Maar je kunt natuurlijk wel voor de ingang gaan liggen en bedelen of je naar binnen mag. Of je kunt met vleierij, listige kunstgrepen, dreiging met geweld of anderszins een plekje proberen te bemachtigen. Missing out is not an option.
Ten eerste vanwege de onweerstaanbare termen sovereignty en gpt-nl. Vang ons tijdsgewricht maar eens compacter.
Ten tweede omdat Jakub Zavrel erbij betrokken is. En ik ben aspirant-lid van de Zavrel fanclub.
Sinds 2007.
Ik weet nog wanneer dat begon. In 2007.
(meer…)
Op techcrunch kon je gisteren lezen dat ChatGTP zich tegenwoordig baseert op Grok.
Dat is dus wat je moet begrijpen.

AI is slim geworden door alle gegevens op het web op te slurpen. Maar die bak was snel leeg. AI’s storten zich sindsdien op nieuwe gegevens. Maar steeds meer van die gegevens hebben ze zelf ‘geproduceerd’.
Modellen trainen steeds meer op afgeleide output, waardoor informatiedichtheid afneemt. Ofwel, AI praat steeds meer poep.
(meer…) People aggregator Eightfold bevindt zich op dit moment in het oog van een publiciteiteitsstorm doordat een tweetal consumenten een class action lawsuit tegen het bedrijf hebben aangespannen.
People aggregator Eightfold bevindt zich op dit moment in het oog van een publiciteiteitsstorm doordat een tweetal consumenten een class action lawsuit tegen het bedrijf hebben aangespannen.
Iets meer over Eightfold
Eightfold AI heeft in totaal 5 investeringsrondes (Series A tot en met Series E, 20217 – 2021) doorlopen. Met deze rondes heeft het bedrijf een totaalbedrag van ongeveer $410 miljoen opgehaald. Als ik me goed herinner, heeft Eightfold met de Series D ronde de begeerde unicorn status bereikt. Ondertussen is Eightfold aanzienlijk meer waard. Eighfold heeft in de afgelopen jaren een indrukwekkend corporate klantenbestand opgebouwd, naast samenwerkingen met SAP (Meer dan de helft van de Eightfold-klanten gebruikt SAP SuccessFactors). Eightfold is volledig geïntegreerd via SAP’s eigen API’sen Salesforce (Agentforce, Skill trends)
 Vrijblijvend leesadvies: Disposition Data: The Asset That Became a Liability. Dit artikel van Martyn Redstone is wederom een pareltje en gaat ook nog eens over een zeer actueel onderwep: disposition data.
Vrijblijvend leesadvies: Disposition Data: The Asset That Became a Liability. Dit artikel van Martyn Redstone is wederom een pareltje en gaat ook nog eens over een zeer actueel onderwep: disposition data.
In dit artikel analyseert Redstone waarom het hergebruik van disposition data voor het trainen van AI-systemen niet langer een waardevol bezit is, maar een groot juridisch risico is geworden. De belangrijkste punten uit het artikel zijn: